| |
Home | Download | Support |
| Understanding Expokit | |
|
(1) | |||||||||||||||||||||||||||||
|
(2) |
When u = 0, the solution is simply w(t) = exp(tA)v. Expokit provides
user-friendly routines (in Fortran 77 and Matlab) for addressing
either situation (case u = 0 and case u ![]() 0). Routines for computing small matrix
exponentials in
full are provided as well. The backbone of the sparse routines
consists of Krylov subspace projection methods (Arnoldi and Lanczos
processes) and that is why the toolkit is capable of coping with
sparse matrices of very large
dimension. The package handles real and
complex matrices and provides specific routines for symmetric and
Hermitian matrices. When dealing with Markov chains, the computation
of the matrix exponential is subject to probabilistic constraints. In
addition to addressing general matrix exponentials, a distinct
attention is assigned to the computation of transient states of Markov
chains.
0). Routines for computing small matrix
exponentials in
full are provided as well. The backbone of the sparse routines
consists of Krylov subspace projection methods (Arnoldi and Lanczos
processes) and that is why the toolkit is capable of coping with
sparse matrices of very large
dimension. The package handles real and
complex matrices and provides specific routines for symmetric and
Hermitian matrices. When dealing with Markov chains, the computation
of the matrix exponential is subject to probabilistic constraints. In
addition to addressing general matrix exponentials, a distinct
attention is assigned to the computation of transient states of Markov
chains.
The purpose of this cursory introduction is to let the reader catch a glimpse of the fundamental elements that make Expokit so fast and robust. The large sparse matrix exponential situation (case u = 0) is taken as the basis of the exposition.
To compute w(t) = exp(tA)v, the Krylov-based algorithm of Expokit purposely sets out to compute the matrix exponential times a vector rather than the matrix exponential in isolation.
Given an integer m, the Taylor expansion
|
(3) |
| c0v + c1(tA)v + c2(tA)2v + ... + cm-1(tA)m-1v |
|
(4) |
| [V,H, |
v1 := v/ for j := 1:m do p := Avj for i := 1:j do hij := viTp p := p - hijvi end hj+1,j := ||p||2 vj+1 := p/hj+1,j end |
From the starting vector v, if the Arnoldi procedure is applied simply with A (rather than tA), then upon completion it builds two matrices
|
H |
= [hij] |
|
| The matrices |
H |
and | Hm | have a special form |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
For any
arbitrary scalar ![]() , Km(
, Km(![]() A,v) = Km(A,v),
and in fact, multiplying (5) and (6) by
A,v) = Km(A,v),
and in fact, multiplying (5) and (6) by
![]() shows that it is
straightforward to extend these relations to
shows that it is
straightforward to extend these relations to
![]() A using
A using ![]() Hbar and
Hbar and ![]() Hm with Vm+1
unchanged. Hence there is no loss of generality when applying the
Arnoldi procedure directly to A.
Hm with Vm+1
unchanged. Hence there is no loss of generality when applying the
Arnoldi procedure directly to A.
These key observations are vital to the overall Krylov solution technique.
Let wopt be the
optimal Krylov approximation in the least squares sense to w(![]() ) = exp(
) = exp(![]() A)v. Since Vm is a basis of
the Krylov subspace,
wopt = Vmyopt with yopt
A)v. Since Vm is a basis of
the Krylov subspace,
wopt = Vmyopt with yopt
![]() Rm.
Thus
by defintion we have
Rm.
Thus
by defintion we have
|
|
(7) |
|
(8) |
|
H |
m+1 = [ |
H |
| 0] |
|
H |
m+1)e1 = pm( |
It is
known from the theory of matrix functions that
exp(![]() A)v = pn-1(
A)v = pn-1(![]() A)v where pn-1
is the
Hermite interpolation polynomial of the exponential function at
Eig(
A)v where pn-1
is the
Hermite interpolation polynomial of the exponential function at
Eig(![]() A). From the
theory of Krylov subspaces, Eig(
A). From the
theory of Krylov subspaces, Eig(![]() Hm) not only approximates a
larger subset of Eig(
Hm) not only approximates a
larger subset of Eig(![]() A)
as m increases but also
approximates it more accurately. These results further provide a
stimulus for using these approximations. In our implementation, we
use the corrected approximation (8) exclusively.
A)
as m increases but also
approximates it more accurately. These results further provide a
stimulus for using these approximations. In our implementation, we
use the corrected approximation (8) exclusively.
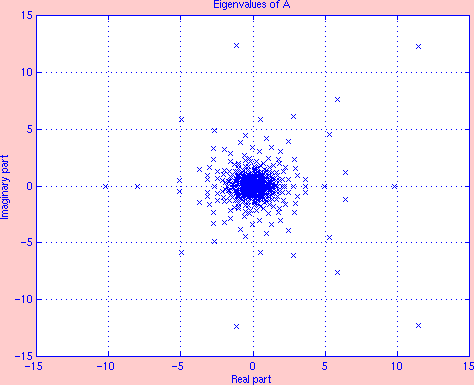 Spectrum
|
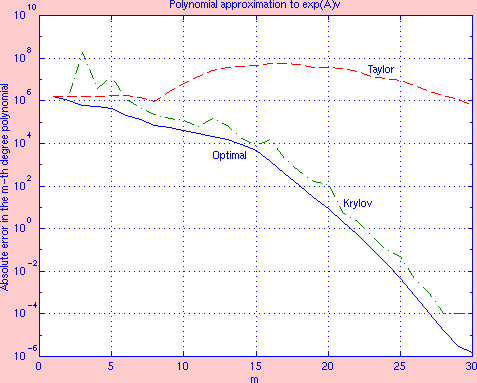
For a random v and A of order 500 whose spectrum Eig(A) is given on the first figure, the second figure shows three error curves corresponding to ||wexact - wmthapprox||2, with wexact = exp(A)v and wmthapprox is either the m-th degree optimal approximation, the m-th degree Krylov approximation in (8), or the m-th degree truncated Taylor approximation. As m gradually increases from 1 to 30, the optimal error and the Krylov error decrease significantly from 106 to 10-6.
As illustrated graphically, this relatively easy to get Krylov
approximation is not the optimal one but as m augments, it quickly
draws close to the optimal and it is better than the m-fold
Taylor expansion - which highlights that for the same amount of
matrix-vector products, the Krylov approximation is better than the
Taylor approximation. However, the Krylov approach needs more room
(especially to store V ![]() Rn×(m+1)) and involves more
local calculation (notably the Arnoldi sweeps needed to construct V
and Hbar). Hochbruck and Lubich have
shown that the error in the Krylov approximation behaves like O(e-
Rn×(m+1)) and involves more
local calculation (notably the Arnoldi sweeps needed to construct V
and Hbar). Hochbruck and Lubich have
shown that the error in the Krylov approximation behaves like O(e-![]() ||A||2[(
||A||2[(![]() ||A||2e)/ m]m)
when m
||A||2e)/ m]m)
when m ![]() 2
2![]() ||A||2.
||A||2.
Krylov approximation
w := v; |
|
(9) |
| k = 0, 1, ..., s, |
Consequently, in the course of the integration, one can output
intermediate discrete observations (if they are needed) at no extra
cost. The {![]() k}
are step-sizes that are selected automatically within the code to
ensure stability and accuracy. This time-stepping selection is done in
conjunction with error estimations. Nevertheless it remains clear
from (9) that the crux of the problem at each
stage is an operation of the form exp(
k}
are step-sizes that are selected automatically within the code to
ensure stability and accuracy. This time-stepping selection is done in
conjunction with error estimations. Nevertheless it remains clear
from (9) that the crux of the problem at each
stage is an operation of the form exp(![]() A)v, albeit with different
A)v, albeit with different ![]() 's and v's. The selection of a specific
step-size
's and v's. The selection of a specific
step-size
![]() is made so that exp(
is made so that exp(![]() A)v is now effectively
approximated by (8) using information of the
current Arnoldi process for the stage. Following the procedures of
ODEs solvers, an a posteriori error control is carried out to
ensure that the intermediate approximation is acceptable with respect
to expectations on the global error. Further information and
references may be obtained from the Expokit documentation.
A)v is now effectively
approximated by (8) using information of the
current Arnoldi process for the stage. Following the procedures of
ODEs solvers, an a posteriori error control is carried out to
ensure that the intermediate approximation is acceptable with respect
to expectations on the global error. Further information and
references may be obtained from the Expokit documentation.